Search with ML - Course Recap
March 23, 2022

Introduction
Search is a field that requires continuous learning in order to stay ahead of the curve. As a UX designer who works closely with search engineers, knowing just enough about the underlying technology helps me dramatically. In an effort to enhance my knowledge of how an AI-powered search engine works, I recently completed an intense 4-week course called “Search with Machine Learning by co:rise”.
This course gave me the skill set necessary to apply machine learning for search problems. I was also able to brush up on my search relevance skills. The course was structured in weekly topics that included:
- Week 1 — Search 101: Indexing & Hand Relevancy Tuning
- Week 2 — Learn to Rank: Using machine learning to tune relevancy
- Week 3 — Content Understanding: Annotating content in the search engine for better relevance
- Week 4 — Query Understanding: Using the context in the user's query and past behavior to improve relevancy.
Background
I initially learned about Search with ML through the Search Relevance & Matching Tech Slack group— (which is another helpful resource I would recommend for staying on top of search technologies). It is led by two industry experts Grant Ingersol and Daniel Tunkelang, authors of two great resources, Taming Text and Query Understanding, both of which I've read in the past. I thought this would be a unique opportunity to learn directly from them.
Though I wasn't sure I had the time or qualifications to complete the work, I decided that I would give it a shot and I'm really glad I did.
One of the most helpful and energizing parts of taking this course was the built-in community—a group of 140 search engineers, designers, and product managers. It was really inspiring to see everyone's progress. Every day I saw others' homework assignments and questions that gave me confidence in the skills I have and the motivation to keep plugging away.
Ultimately, I learned a ton of new skills. Here's a breakdown of my key learnings from this course:
Key Learnings
1 — Importance of indexing, keep iterating on your index
We started the course indexing documents. Without mappings defined, you can still index documents and your search engine will guess about what it thinks the fields in the document contain, often it will guess incorrectly (ex. booleans or numbers as keywords). Once you properly "map" these fields your search relevancy will start to improve.
I quickly learned to work iteratively on this process indexing frequently and testing the results repeatedly. During a project session, I explained I was "getting ready" to start indexing my content. I was reminded that this was a common error for new search engineers.
https://twitter.com/clintonhalpin/status/1495395976198201348
2 — Hand Tuned queries
The end result of any search request ends up being a blob of JSON. Building my search first search requests by hand took hours of iteration. I quickly learned to work in the Open Search devtools. Iterating on search requests and leveraging autocomplete along the way. Then I could move to implementation in python.
3 — To improve search we have to measure it
Simple MRR is 0.301
LTR Simple MRR is 0.302
Hand tuned MRR is 0.392
LTR Hand Tuned MRR is 0.522
...
LTR hand tuned p@10 is 0.263
Simple better: 67 LTR_Simple Better: 144 Equal: 2416As we moved into the second week we were focused on using machine learning to improve our search results specifically Learn to Rank (LTR).
We first started by evaluating our search engine manually. Then learned about precision & recall. Finally, we talked about how we could use these metrics to calculate the most frequently used search metrics—Mean reciprocal Rank (MRR) and Discounted cumulative gain (NDGC).
Search relevance and quality are subjective. As search engineers, we need to arm ourselves with data to measure quality. We can use these metrics to track incremental improvements along the way.
4 — Known Item vs. Exploratory Search
We focused on understanding "search relevancy" throughout the course. From the different types of search engines and how each type may present unique requirements for precision and recall. As well as unique user intents.
One topic that spanned all search intents was the distinction between item lookup vs. exploratory search. Here is a helpful description:
| Intent | Description |
|---|---|
| Known Item search | Users who enter a search query with an item already in mind Ex. looking for a TV of a specific size or brand, an Item SKU |
| Exploratory search | Users who use search to narrow down an idea in their mind. The classic quote here was “I know it when I see it” |
5 — Machine Learning: Garbage in and Garbage Out
Training data
__label__abcat0101001 lcd tv
__label__pcmcat158900050018 projector
__label__abcat0403004 flip video camera
__label__cat02015 darker than black
__label__cat02015 appl
Test data
__label__cat02015 make the grade
__label__abcat0504010 usb memori
__label__abcat0703002 star war 3
__label__abcat0208011 bose portabl
__label__pcmcat218000050003 ipod casePrepping "unbiased" training and test data for query understanding
Over the 4 weeks, it was clear the importance of quality training and testing data to build better machine learning models. We did so much data cleaning, sampling, and filtering to create "unbiased" training sets. Data analysis is a critical skill.
6 — LTR is based on the Rescore Function
When utilizing Learn to Rank, you train your model on past behavior. We fetched a large number of search results then used features stored in our LTR model to sort the results improving the precision at the top of the list.
Preparing quality unbiased training data was critical to good LTR.
https://twitter.com/clintonhalpin/status/1498305062489276424?s=21
query_obj["rescore"] = {
"window_size": rescore_size,
"query": {
"rescore_query": {
"sltr": {
"params": {
"keywords": user_query,
"click_prior_query": click_prior_query,
},
"model": ltr_model_name,
"store": ltr_store_name,
}
},
"score_mode": "total",
"query_weight": main_query_weight,
"rescore_query_weight": rescore_query_weight
},
}7 — LTR Features: Query dependent vs. Query independent features
Setting up the "plumbing" for an LTR model was time-consuming, both prepping the data implementing the needed functions. We then moved on to building features that LTR could tune results with. A key distinction we learned about was the different types of features an LTR model could tune.
| Feature | Description |
|---|---|
| Query Dependent | Features, which depend both on the contents of the document and the query ex. TF-IDF, BM25, Field Analyzers |
| Query Independent | Features, which depend only on the document, but not on the query. ex. Popularity, Rank, Price |
8 — Fast Text for Word Embeddings
We used fastText to help us understand the content and queries. The workflow was broadly focused around prepping training and test data. Then tuning the library and experimenting with different parameters to improve Precision and recall.
| Query | Neighbors |
|---|---|
| Phone | motorola (0.96), cell (0.95), mobil (0.95), verizon (0.94), earphon (0.94), tmobil (0.94), nocontract (0.94), gophon (0.94), htc (0.94), droid (0.94) |
| Camera | xs (0.99), vr (0.99), rebel (0.99), dslr (0.99), slr (0.99), nikon (0.99), zoom (0.99), finepix (0.99), cybershot (0.99), sigma (0.99) |
| Laptop | processor (0.98), gateway (0.97), drive (0.97), ideapad (0.96), aspir (0.96), pavilion (0.96), vaio (0.96), ideacentr (0.96), duo (0.96), display (0.96) |
9 — Content Understanding
curl -XPOST -s http://localhost:5000/documents/annotate -H "Content-Type:application/json" -d '{"name":"laptop", "sku":"abc"}'
{
"name_synonyms": [
"processor",
"gateway",
"drive",
"ideapad",
"aspir",
"pavilion",
"vaio",
"ideacentr",
"duo",
"display"
]
}One of the core ways to improve search relevancy happens before documents are indexed. During this portion of the course, we worked on classifying content into more useful buckets. As well as annotating content with synonyms to make it more discoverable. For both of the processes, we used fastText to build models based on previous data enriching each document in our index.
10 — Query Understanding
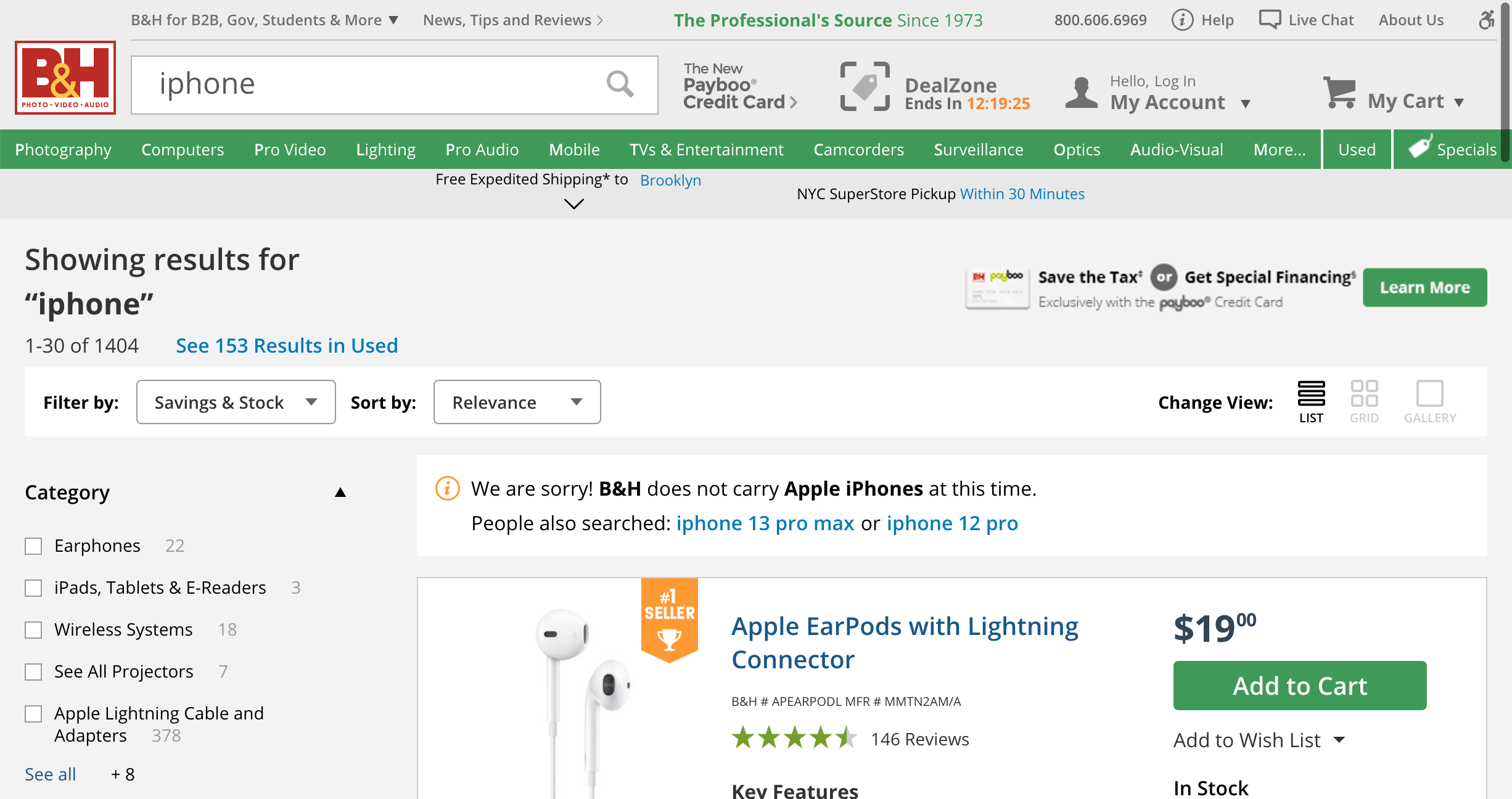
An example from the course. Users searching for iphones on a photo site!
Query understanding is the process of transforming a search query to better represent the underlying search intent. We explored query rewriting and query classification to improve results. Boosting or filtering results depending on sorting parameters. The impact on relevancy was immediate.
With query understanding product design & UX plays an important role in communicating how the search engine has interpreted a query.
11 — Pandas
I learned to use Pandas to manipulate, filter, and transform large sets of tabular data. Pandas has great statistical features and a SQL-like interface to work with large sets of data without much manual work.
Coming from mostly NodeJS Development pandas is an amazing tool I've already been leveraging it frequently in my day-to-day work!
12 — Jupyter Notebooks
Throughout the course, I learned to use Notebooks to make progress, iterate and track my work. Jupyter was straightforward to set up. Notebooks became helpful to start each week, keeping track of progress. In a notebook, I could jump seamlessly between bash & python. I reduced the amount of iteration time and context switching and had a detailed log of what I had done.
I will use these skills for years to come! I would certainly recommend taking future sessions of this course. https://corise.com/course/search-with-machine-learning